

Version-Control
Aligned with your local env. Branch to experiment!
Pytest-Inspired
Use
assert, parametrize, and simple decorators.Full Flexibility
Use the same evaluator across a dataset or case-by-case
Agent-Friendly
Powerful and compact CLI and SDK for your coding agent to use
Install
Quick Example
Evaluating a simple sentiment analyzer against a ground truth dataset:@parametrize to apply eval to a dataset:
Web UI
Twevals spins up a local Web UI that makes it easy to filter, run, and rerun evals. Do deep analysis on the results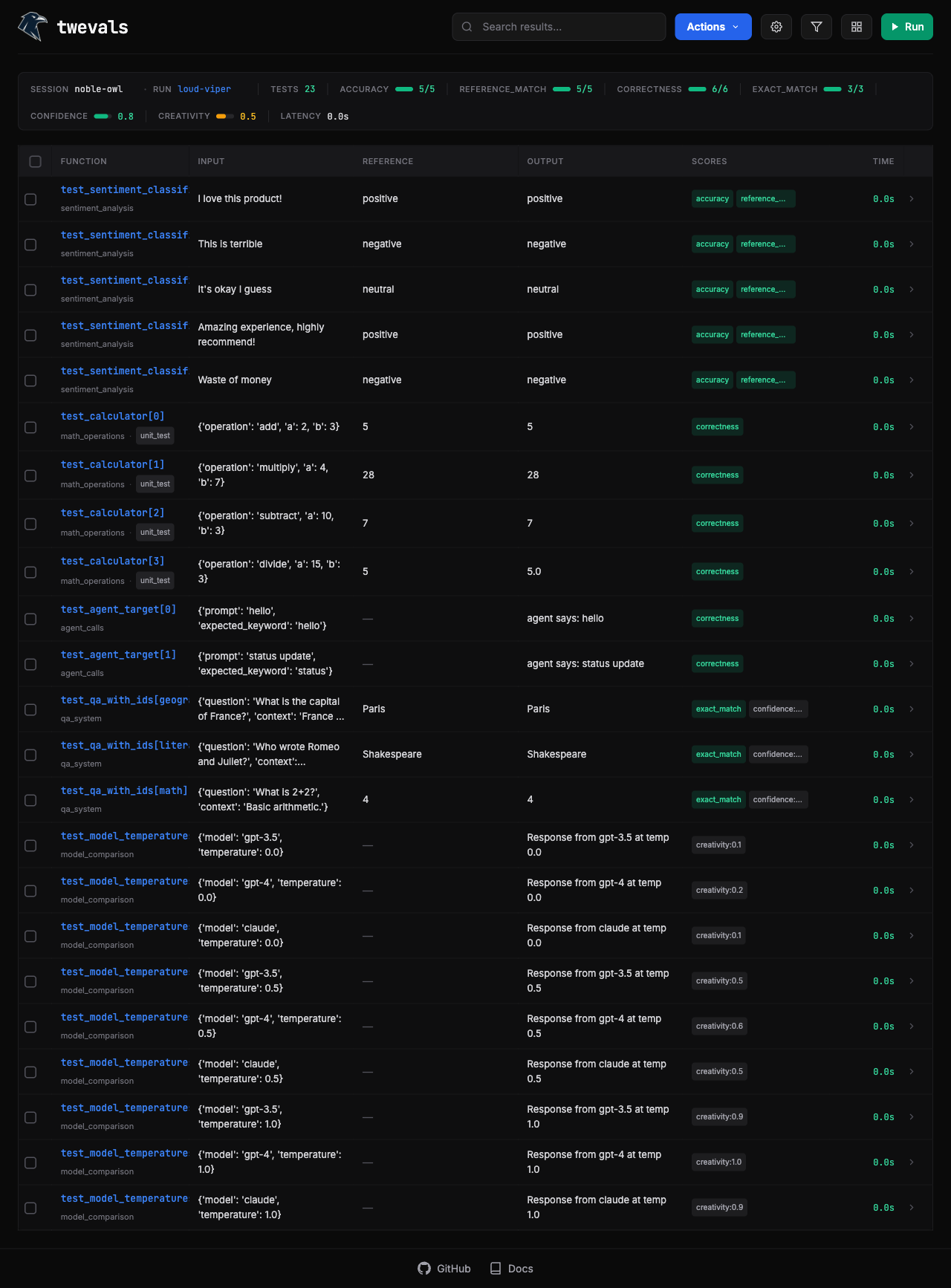
.json file for further analysis.
Agent Mode
The CLI and SDK make it easy for your coding agent to run, analyze, and iterate on the evals!
Can you run test_sentiment_batch evals and tell me why the scores are so low?
Your coding agent would run:
Existing eval frameworks are frustrating:
Too Opinionated
One function per dataset, rigid patterns. No way to run different logic per
test case.
Cloud-Based
Datasets in the cloud. No version control. Code and data live in different
places.
UI-Based
Your coding agent can’t run evals, analyze results, or iterate on datasets.
Ready to start?
Follow our quickstart guide to set up Twevals in under 5 minutes.