Your First Evaluation
Create a file calledevals.py:
Target function
The target function represents the thing you are evaluating. If you are evaluating an agent, your target function would run the agent and return the results. If you are evaluating a single LLM call, the target would just invoke the LLM and return those results. Using atarget function function comes with the added benefits of:
- Latency Tracking - Target function latency will be tracked separately from evaluation latency and is handled automatically
- Reusability - Write one target function and reuse it across many evals
- Prepopulates Context - Useful for injecting data into the context (similar to
beforeEach)
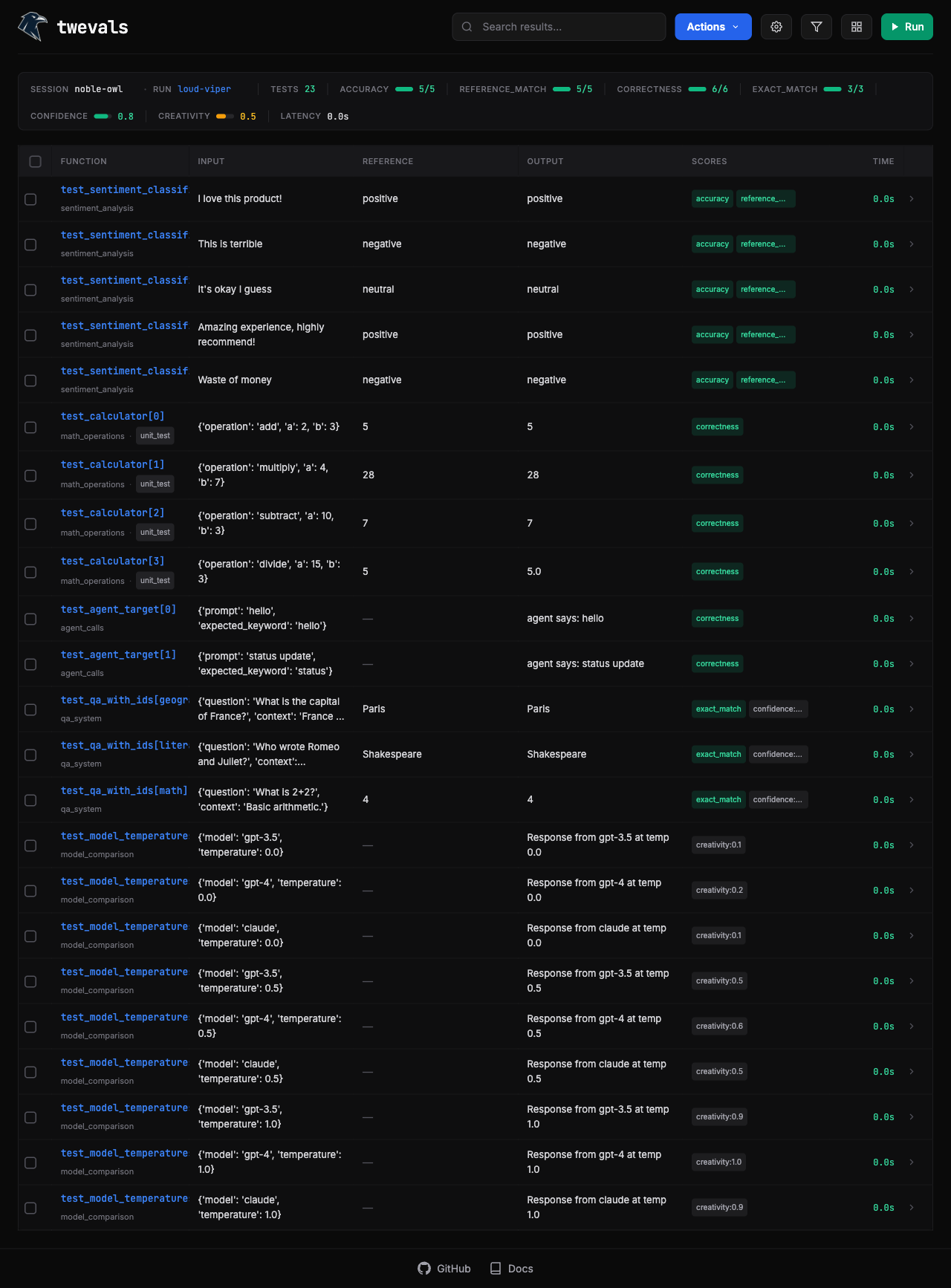
Run Your Evaluations
Start the web UI to run evals and review results:http://127.0.0.1:8000 where you can:
- Run, filter, and rerun specific evals
- Review eval results for analysis
- Annotate results inline
- Export results to JSON or CSV
Agent Mode
When coding agent needs to run evals programmatically, userun:

Add More Test Cases
Use@parametrize to generate multiple evaluations from one function:
input, reference, metadata, run_data, latency) auto-populate context fields. For other parameters, include them in the function signature.
Track Progress with Sessions
Use sessions to group related runs together—useful for comparing models, tracking iterations, or A/B testing:.twevals/runs/ with session metadata, so you can compare runs over time.
Configuration with twevals.json
Create atwevals.json in your project root to set defaults: